[AI] Agent를 쓸 때 Context가 왜 더 중요해질까?
![[AI] Agent를 쓸 때 Context가 왜 더 중요해질까?](https://firebasestorage.googleapis.com/v0/b/cruz-lab.firebasestorage.app/o/images%2Fheroes%2F2026%2F04%2Faiagent-1776856206272-jaufzq.jpg?alt=media&token=d006ff2e-01ce-4faa-b483-ff347bee70ad)
Agent라는 말을 들으면 뭔가 엄청 자율적으로 판단하고 움직이는 존재를 떠올리기 쉽다.
그런데 실제로 다뤄보면, Agent의 성능을 가르는 건 의외로 "얼마나 똑똑한 모델인가"보다 컨텍스트를 어떻게 다루는가에 더 가깝다.
처음 몇 번은 잘 티가 안 난다.
짧은 작업에서는 그냥 "모델이 잘 답하네" 정도로 끝난다.
그런데 조사 좀 길게 붙이고, 도구 몇 번 돌리고, 중간 메모까지 쌓이기 시작하면 분위기가 달라진다.
그때부터는 모델 성능보다 컨텍스트 정리가 더 자주 발목을 잡는다.
Agent는 "대답하는 모델"보다 한 단계 더 많은 걸 한다
일반적인 챗봇은 질문 하나 받고 답 하나 내놓으면 끝난다.
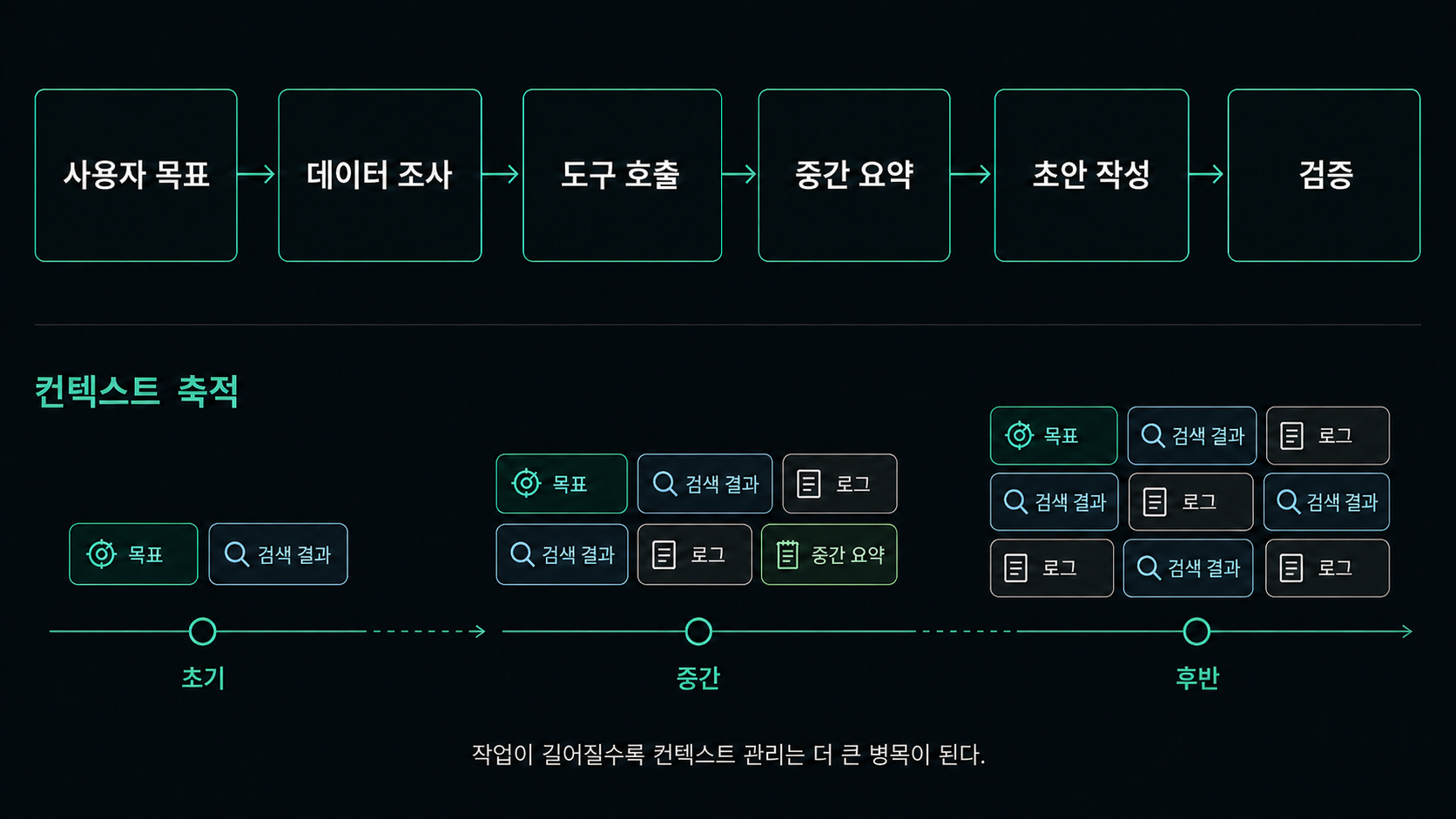
Agent는 그보다 일이 길다.
한 번 답하고 끝나는 게 아니라, 중간 상태를 들고 다음 행동을 계속 붙인다.
- 목표를 받고
- 필요한 하위 작업을 나누고
- 도구를 선택하고
- 중간 결과를 저장하고
- 다음 행동을 결정한다
이렇게 보면 Agent는 단순 응답기라기보다
상태를 들고 도는 작업 루프에 가깝다.
문제는 여기서 바로 생긴다.
이전 단계에서 뭘 했는지,
도구가 뭘 반환했는지,
원래 목표가 뭐였는지,
지금까지 어떤 제약이 쌓였는지를 계속 기억해야 한다.
짧게 끝나는 작업이면 그럭저럭 버틴다.
하지만 흐름이 길어질수록 "지금 뭘 보고 판단하고 있지?"가 금방 흐려진다.
여기서부터 컨텍스트가 핵심이 된다.
Context Window는 메모리가 아니라 작업 공간에 가깝다
보통 Context Window를 "모델의 메모리"처럼 설명하곤 한다.
아예 틀린 비유는 아니다.
그래도 막상 써보면 현재 작업대의 크기라고 보는 쪽이 훨씬 감이 잘 온다.
작업대가 넓으면 많은 걸 펼쳐놓을 수 있다.
대신 정리가 안 되면 오히려 중요한 걸 놓치기 쉬워진다.

Context Window가 작으면?
- 필요한 정보가 잘린다
- 과거 결정이 사라진다
- 같은 실수를 반복한다
Context Window가 크면?
- 더 많은 정보를 유지할 수 있다
- 긴 대화를 이어갈 수 있다
- 복잡한 작업도 한 번에 다룰 수 있다
여기서 헷갈리기 쉽다.
창이 크면 무조건 낫다고 생각하기 쉽기 때문이다.
그런데 막상 써보면 꼭 그렇지는 않다.
좁으면 정보가 떨어져 나가고, 넓으면 잡동사니가 쌓인다.
결국 중요한 건 크기보다 지금 작업대가 얼마나 정리돼 있느냐다.
Context Rot는 "많이 넣을수록 좋아진다"는 착각을 깨뜨린다
Agent를 오래 돌리다 보면 한 번쯤 이런 느낌이 온다.
"분명 정보는 다 줬는데 점점 판단이 흐려진다."
이때 자주 나오는 현상이 흔히 말하는 Context Rot다.
정식 용어처럼 딱딱하게 들릴 수도 있는데, 실제로는 현상 설명에 더 가깝다.
그래도 오래 돌려보면 무슨 말인지 바로 온다.
- 초반의 중요한 제약을 뒤에서 잊어버리거나
- 오래된 중간 결과를 최신 사실처럼 다루거나
- 불필요한 로그와 장황한 사고가 작업대를 점령하거나
- 같은 정보가 중복돼 들어가 핵심 신호가 묻히는 현상
컨텍스트가 커진다고 기억력이 곧장 좋아지는 건 아니다.
잡음도 같이 커진다.
처음엔 정보가 많아져서 더 안전해지는 것처럼 보인다.
그런데 어느 지점을 넘기면 반대로 핵심이 안 보이기 시작한다.
그래서 Agent에서는 최대 길이보다
현재 단계에 필요한 정보만 남기는 능력이 더 중요해진다.

싱글 에이전트는 단순하고 강력하다. 대신 작업대가 금방 더러워진다
싱글 에이전트 방식은 말 그대로 하나가 처음부터 끝까지 다 본다.
작은 작업에서는 이게 제일 편하다.
굳이 역할 나누고 handoff 만들고 상태를 따로 쪼갤 필요가 없기 때문이다.
- 설계가 쉽다
- 상태 관리가 단순하다
- 작은 작업에서는 오히려 가장 빠르다
문제는 작업이 길어질수록 한 에이전트의 컨텍스트 안에
- 목표
- 중간 산출물
- 실패한 시도
- 도구 출력
- 새 제약
가 전부 누적된다는 점이다.
혼자서 다 하는 구조는 편하다.
대신 작업대가 금방 더러워진다.
처음엔 깔끔하다가도, 조사와 작성과 검증이 한 창에 같이 붙기 시작하면 금방 지저분해진다.
짧은 작업에는 좋지만, 흐름이 길어질수록 불리해지는 이유가 여기 있다.

멀티 에이전트는 컨텍스트를 분리하는 방식이다
멀티 에이전트 얘기를 하면 보통 "여러 AI가 협업한다"는 그림부터 떠올린다.
그런데 실제로 써보면 시선이 가는 지점은 다른 데 있다.
핵심은 컨텍스트를 역할별로 나눌 수 있다는 점이다.
예를 들어,
- 조사 에이전트는 자료만 찾고
- 작성 에이전트는 글 구조와 문장을 다듬고
- 검증 에이전트는 사실 관계만 체크하고
- 조정 에이전트는 최종 결론만 정리할 수 있다
이렇게 나누면 각 에이전트는 자기 일에 필요한 정보만 본다.
멀티 에이전트는 성능 마법이라기보다
컨텍스트 오염을 줄이기 위한 분업 전략으로 보는 편이 더 현실적이다.
물론 공짜는 아니다.
- 에이전트 간 handoff 비용이 생기고
- 결과를 다시 통합해야 하고
- 잘못 나누면 오히려 비효율적이다
그래서 무조건 멀티가 답은 아니다.
작고 짧은 일은 싱글 쪽이 훨씬 덜 번거롭다.
다만 작업이 길고, 조사와 작성과 검증처럼 다른 종류의 사고가 한꺼번에 섞일수록 분리의 이점이 커진다.
토큰 메모리 효율을 높이려면 결국 정리를 잘해야 한다
Agent를 오래 굴릴수록 중요한 건 더 많이 넣는 게 아니라 덜 어지럽히는 일이다.
로그는 계속 불어나고, 중간 판단은 금방 낡고, 예전 결정을 다시 찾는 일도 생각보다 자주 생긴다.
이 지점부터는 "더 넣기"보다 "어떻게 남길지"가 더 중요해진다.
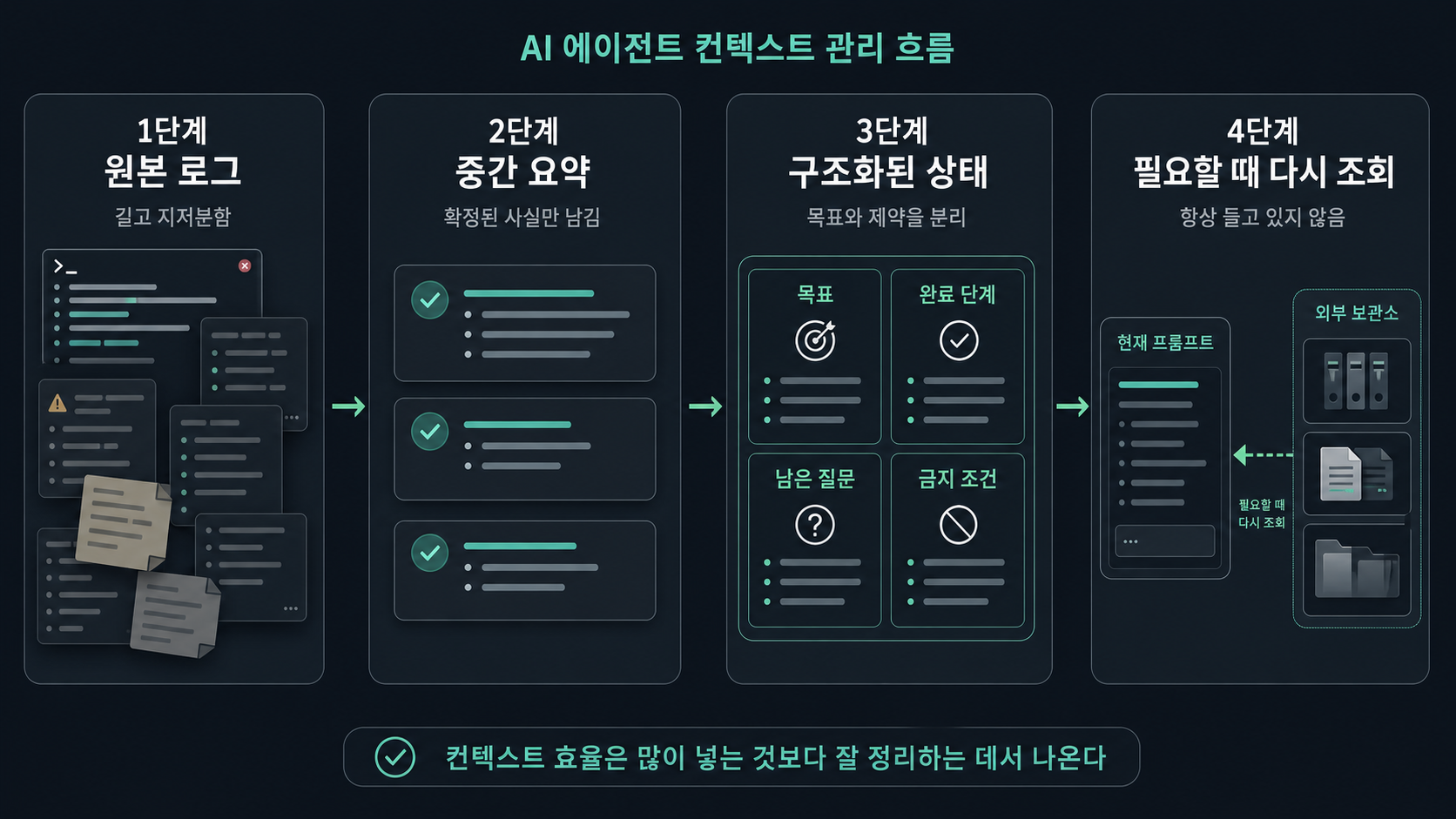
내가 중요하다고 보는 방법은 이런 것들이다.
1. 로그와 결과를 분리한다
도구 실행 로그 전체를 계속 들고 있으면 금방 무거워진다.
- 최종 결과
- 실패 원인
- 다음 단계에 필요한 요점
만 남기고 긴 로그는 버리거나 외부 저장소로 빼는 편이 낫다.
기록을 없애자는 얘기는 아니다.
계속 들고 다닐 것과 나중에 다시 꺼내올 것을 분리하자는 쪽에 가깝다.
2. 중간 요약을 만든다
긴 작업에서는 일정 구간마다 "지금까지 확정된 사실"만 요약한 체크포인트가 필요하다.
이 요약이 있으면 예전 대화를 통째로 다시 넣지 않아도 된다.
이게 없으면 같은 대화를 계속 길게 끌고 가게 된다.
그러면 나중에는 뭐가 확정이고 뭐가 임시 메모였는지도 흐려진다.
3. 구조화된 상태를 따로 둔다
자유 텍스트만으로 상태를 들고 가면 금방 흐려진다.
예를 들어 이런 식의 구조가 유용하다.
- 목표
- 완료된 단계
- 아직 남은 질문
- 금지 조건
- 최종 산출물 형식
이걸 별도 상태처럼 관리하면 컨텍스트가 훨씬 덜 흐트러진다.
자유 텍스트만 길게 쌓아두는 것보다, 이런 식으로 상태를 따로 세워두는 편이 훨씬 덜 헷갈린다.
4. retrieval을 붙인다
모든 걸 항상 프롬프트 안에 넣어둘 필요는 없다.
자주 안 쓰는 정보는 바깥에 두고,
지금 단계에서 필요한 것만 다시 꺼내오는 쪽이 훨씬 안정적이다.
5. 역할을 나눌 수 있으면 나눈다
하나의 에이전트가 조사, 작성, 검증을 다 하면 금방 엉킨다.
일이 길어지면 역할을 분리해서 컨텍스트도 같이 분리하는 편이 좋다.
결국 앞에서 말한 싱글 vs 멀티 얘기도 여기로 돌아온다.
길게 가는 작업일수록 역할 분리가 곧 문맥 정리가 된다.
마무리
Agent를 잘 만든다는 건 결국
지금 단계에 필요한 정보만 제때 꺼내 쓸 수 있게 만드는 일에 더 가깝다.
모델 성능이 중요하지 않다는 얘기는 아니다.
다만 실제로 길게 돌려보면, 더 자주 문제를 만드는 쪽은 컨텍스트다.
창이 좁아서 잘리는 문제도 있고,
넓은데 어질러져서 핵심이 묻히는 문제도 있고,
한 에이전트에 다 몰아넣어서 점점 흐려지는 문제도 있다.
내가 보기엔 좋은 Agent는 말 잘하는 모델 하나에서 나오지 않는다.
정보를 어떻게 정리하고, 무엇을 남기고, 무엇을 바깥으로 빼두고, 언제 다시 꺼내올지에서 갈리는 경우가 더 많다.